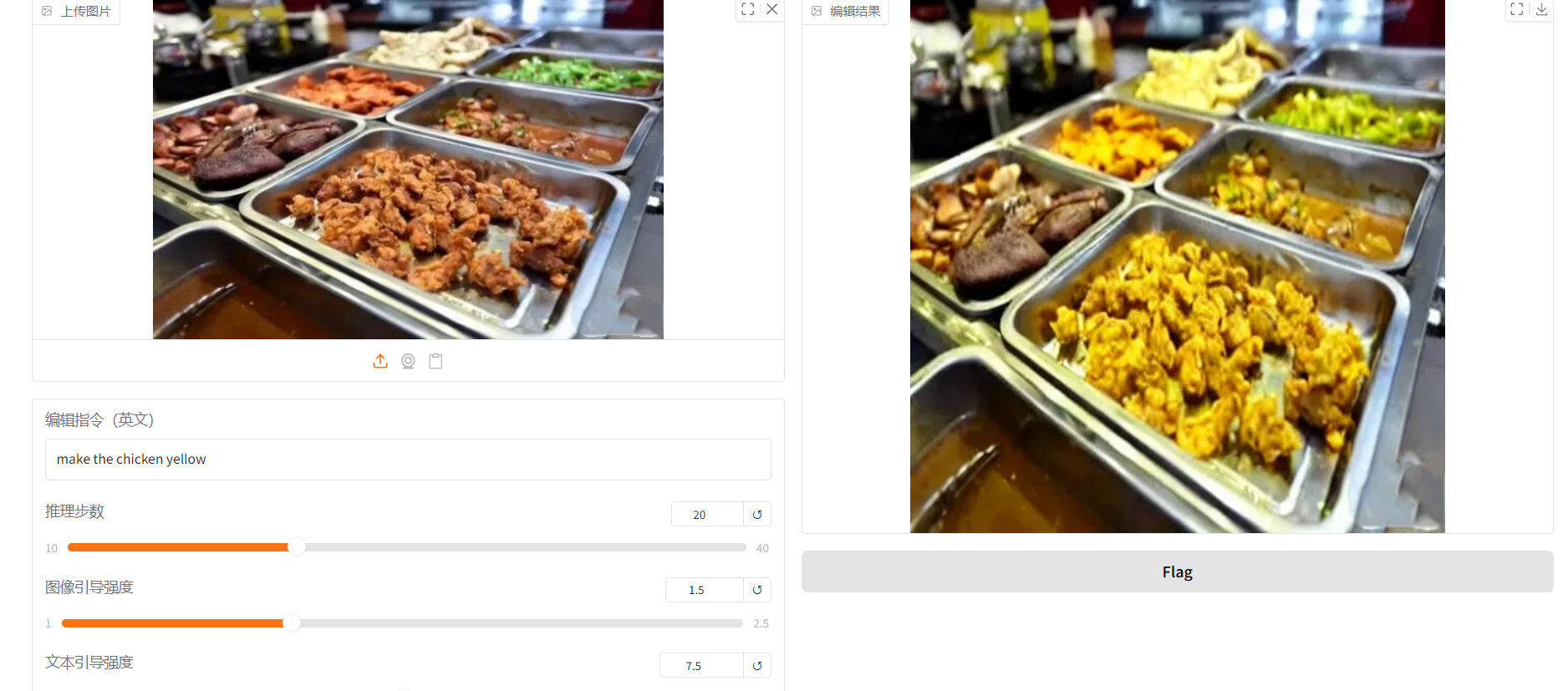
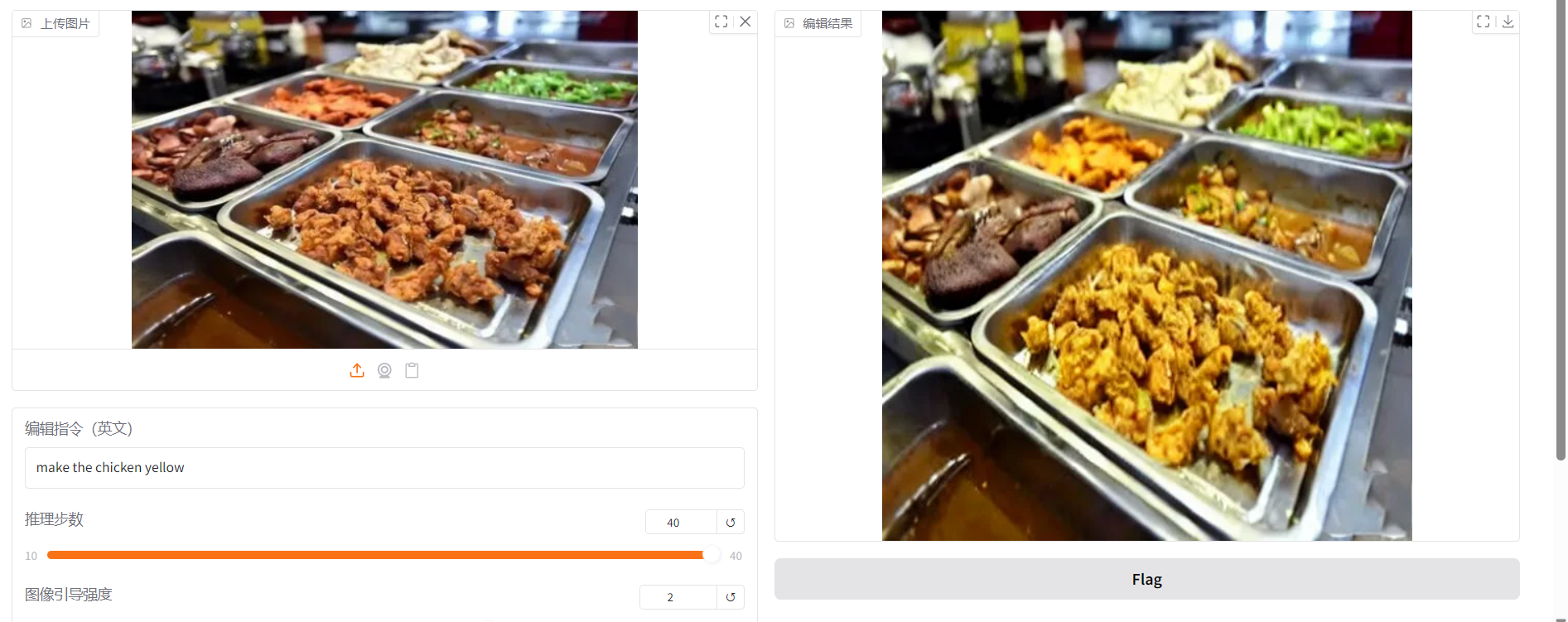
已完成面向用户自定义输入的文字驱动图像编辑实验,系统能够接收用户上传图像与文本编辑指令,并生成对应编辑结果,初步验证了模型在人物属性修改任务中的可行性。
把编辑过程封装成函数
已基于 Gradio 完成文字驱动图像编辑原型系统界面,实现了用户上传图像、输入文本编辑指令并返回编辑结果的基础交互流程。
1)推理步数 num_inference_steps
它表示模型“迭代修图”的次数。步数越高,模型有更多轮去噪和细化,通常画面会更完整、更稳定,但速度会更慢;官方文档的原话就是“更多去噪步数通常会带来更高质量图像,但代价是更慢的推理”。不过它不是无限增益,到了某个范围以后,继续拉高提升会变小。
2)文本引导强度 guidance_scale
这个参数控制模型“听 prompt 的程度”。数值越高,结果越努力去满足你输入的英文指令,比如你写 make the chicken yellow,它就会更激进地往“黄色鸡肉”这个方向改。官方文档说明,更高的 guidance_scale 会让结果更贴近文本,但通常会牺牲一些图像质量。也就是说,它高了不一定更自然,只是更“听话”。
3)图像引导强度 image_guidance_scale
这个参数控制模型“保留原图”的程度。数值越高,输出图越会往输入图靠近,尽量保持原有结构、布局、主体位置不乱。官方文档写得很直接:它会把生成图“推向初始图像”,更高时通常更贴近原图,但也可能牺牲图像质量。对图像编辑任务来说,它本质上是在控制“改动幅度别太离谱”。